 百万个冷知识
百万个冷知识
将HPC的超高INS13ZD搬到云上,什么控制技术路子这么强?
作者 I 心缘
没有云排序厂商,会轻易放过大增成本的机会。
云是今后,这在全球各大信息技术巨擘的新一代半年报中已经得到明确的验证。新一代财季,AWS净销售额环比快速增长27%,微软智能化云总收入环比快速增长20%,谷歌云总收入环比快速增长37%,阿里云销售总收入环比快速增长4%,百度智能化云销售总收入环比快速增长24%……
承载着“让INS13ZD天然资源大众化”使命的云排序,形成了撑起信息技术巨擘今后的新型支柱销售业务。而要持续拉高INS13ZD峰值、提高客户穗序服务新体验,推进构架层的变革已是迫在眉睫。
控制技术插值的Nxd4向前,被冠以网络系统“第二颗主力晶片”的DPU,正成为现代云排序构架云化原生植物DT排序升级的“手牌”。

网络系统下一站:云原生植物DT排序
云是今后,已是毫无疑问。但如何通过云服务向暴涨的使用者同时提供更多更大规模的INS13ZD支持,是摆在每一云大厂面前的核心理念议题。
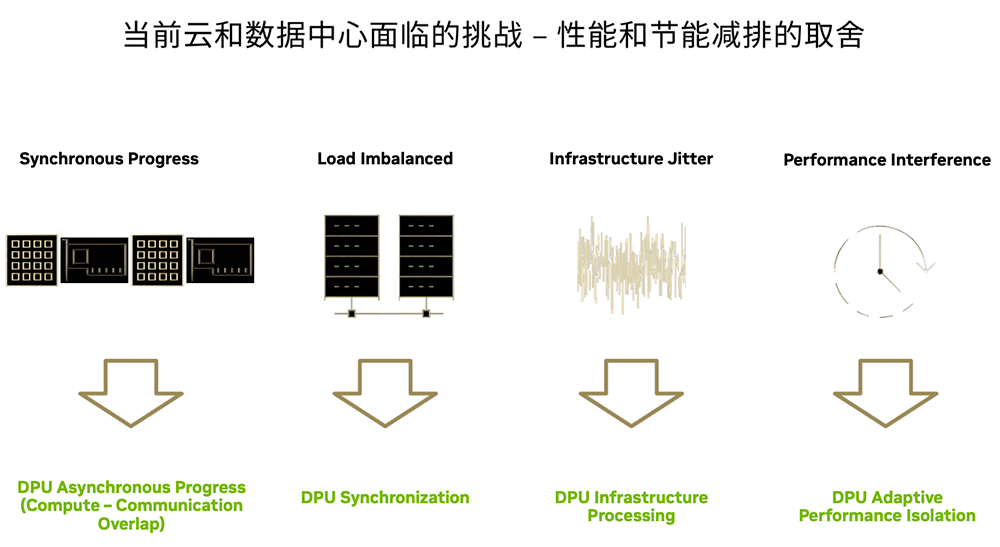 ▲当前云和网络系统面临平衡操控性与能耗的考验(图源:Nvidia)
▲当前云和网络系统面临平衡操控性与能耗的考验(图源:Nvidia)云服务的优势是进料以供、穗序INS13ZD,高效能排序则拥有强大INS13ZD。一种“优势互补”的路子已经开始走向破冰:如果将两者的控制技术路线结合,是不是就能在云上提供更多媲美DT排序机的操控性?
乍一想可行,但落到实处,需化解很多的控制技术考验。在现代云原生植物的INS13ZD基础建设中,CPU是亲力亲为的晶片“大总管”,既要处置排序各项任务,又要监管通讯和储存,忙着这头,就顾不上那头,中间造成大量的排队等候时间和INS13ZD天然资源浪费。
这就好比餐厅,规模小、客人少时,一位大厨还能忙得过来。此时这位大厨包揽了后厨的所有工作,除了忙着做菜外,还操心采买、仓储、切配、端菜等等。然而等客人愈来愈多,如果还靠他亲力亲为,那么做菜效率就低了,每一客人的等菜时间都长,新体验都不好。
为化解这些关键点而生的云原生植物DT排序构架,正在云排序网络系统流行开来。
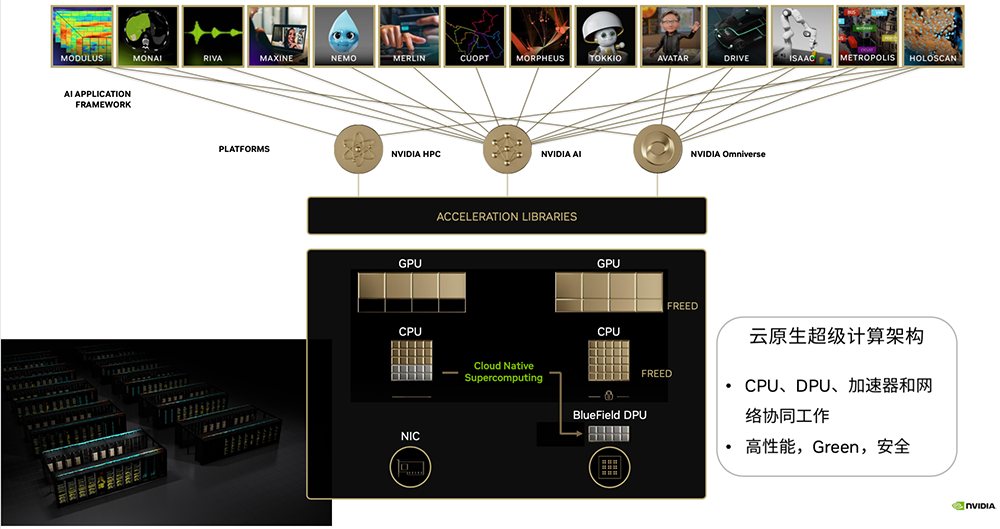 ▲云原生植物DT排序构架(图源:NVIDIA)
▲云原生植物DT排序构架(图源:NVIDIA)云原生植物DT排序的核心理念路子是“地方分权”,相当于给大厨配上Chalancon、服务员等专精阿福,这样一来,大厨能够埋首把菜炒得Accous。
如今,愈来愈多的商业性云已经开始提供更多高效能排序(HPC)云服务,小型INS13ZD服务中心也产生更多的穗序需求。主要承担HPC和小型人工智能化(AI)训练各项任务的INS13ZD服务中心,本身INS13ZD天然资源池非常大,存在INS13ZD天然资源闲置问题。
而引入云原生植物DT排序控制技术,可以将INS13ZD天然资源重新组合供给多使用者多销售业务,通过编排调度,让每一销售业务都能享有堪称独占所有天然资源时的高效能。
无论是从提高操控性、优化设计,抑或是从节能降耗的角度,云原生植物DT排序对于商业性云和小型INS13ZD服务中心的构架优化路子都很有借鉴价值。

给高效能销售业务穗序开路!
解读云原生植物DT排序的灵魂
云原生植物DT排序请的专精阿福,就是DPU。
作为替CPU分摊工作的辅助“大脑”,DPU接手了通讯、储存、安全等各项任务,让CPU能埋首处置使用者销售业务,这样各种排序和通讯各项任务就可以LX1,不再像以往那样出现拥堵问题。
 ▲典型的DPU/DOCA装载及加速通讯流程示意图(图源:NVIDIA)
▲典型的DPU/DOCA装载及加速通讯流程示意图(图源:NVIDIA)经过两年发展,这个被AI排序巨擘NVIDIA(英伟达)催热的晶片新秀,已经已经开始广泛破冰于云排序和高效能排序的INS13ZD基础建设建设大潮中。
具体而言,NVIDIA BlueField DPU对网络系统的最大价值,就是实现操控性和能效的显著提高。
首先是操控性,提高网络系统整体操控性的一大关键阻力是网络。原本排序能力有十成,多个各项任务同时处置后,CPU处置这个排序各项任务或者管理调配通讯、储存等天然资源时,另一个排序各项任务就只能浪费时间等待。此外,如果两个各项任务在通讯过程中狭路相逢,造成网络阻塞,那么就会造成延时。在金融银行等对延时高度敏感的应用场景中,这可能给客户交易造成损失。
而在 NVIDIA BlueField DPU主管网络、储存等基础构架功能后,不仅CPU可以将更多排序天然资源用在云服务客户的销售业务上,整体网络阻塞问题得到明显改善,而且BlueField DPU本身携带的排序天然资源也可以辅助加速排序。
 ▲典型的DPU/DOCA装载及加速通讯流程示意图(图源:NVIDIA)
▲典型的DPU/DOCA装载及加速通讯流程示意图(图源:NVIDIA)再从能效来看,随着网络系统规模愈来愈大,改善耗电量、降低基础建设采购和降低电力成本,已经是优化现代网络系统和主要目标。
引入NVIDIA BlueField DPU,已是较大网络系统提高系统能效的有效途径之一。
在运行基础建设各项任务时,内置专用硬件引擎的NVIDIA BlueField DPU,效率要比CPU高得多。此外,NVIDIA BlueField DPU上的CPU核心理念采用Arm构架,天然比多数x86服务器CPU更加节能,并且可以直接访问网络管线。
换个角度来看,同样的CPU数量,将排序天然资源更集中的供给云服务销售业务后,能够提供更多更高效能。反过来,实现相同的操控性,其实要比以前消耗更少的CPU,这相当于减少了硬件采购成本,进而有助于大幅降低总体拥有成本(TCO)。
根据《NVIDIA BlueField DPU能效白皮书》,通过用NVIDIA BlueField DPU装载,在3年期间将1万台服务器的每台服务器耗电量降低200W,可在中国地区节省的成本估算值接近400万美元(近2800万人民币)。
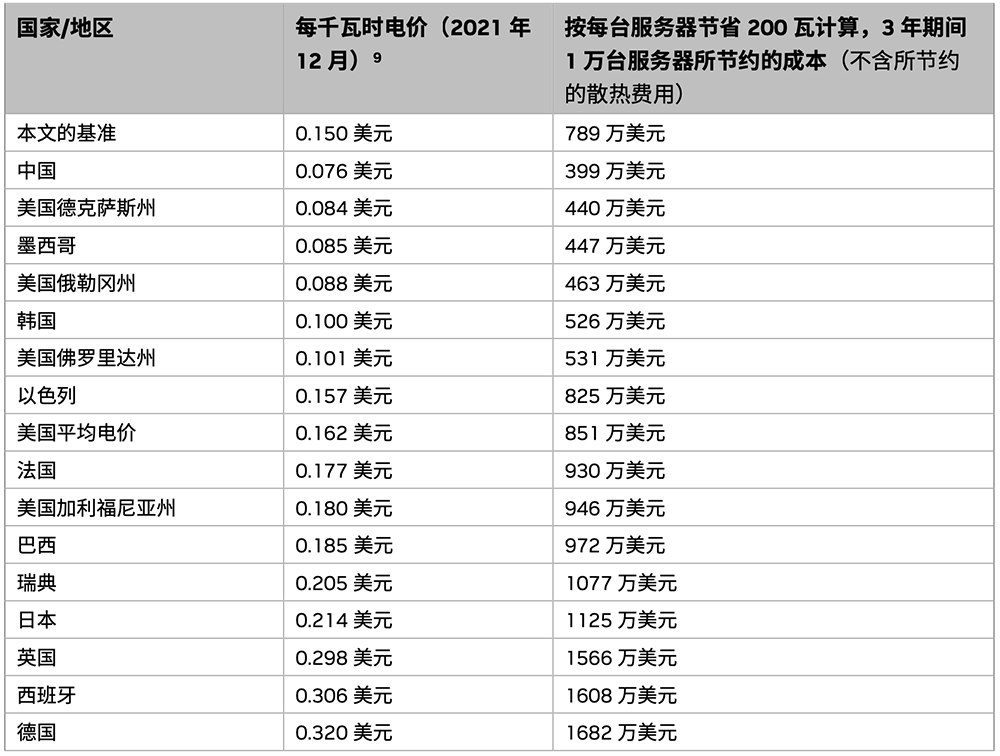
▲根据2020/2021年电价,在不同国家/地区,通过使用DPU装载在3年期间将1万台服务器的每台服务器耗电量降低200瓦,可节省的成本估算值(图源:NVIDIA DPU能效白皮书)
如果为拥有1万台服务器的小型网络系统排序,将IPsec加密/解密装载到NVIDIA DPU,那么小型网络系统的3年TCO有望节省约2630万美元(折合约1.8亿人民币)。
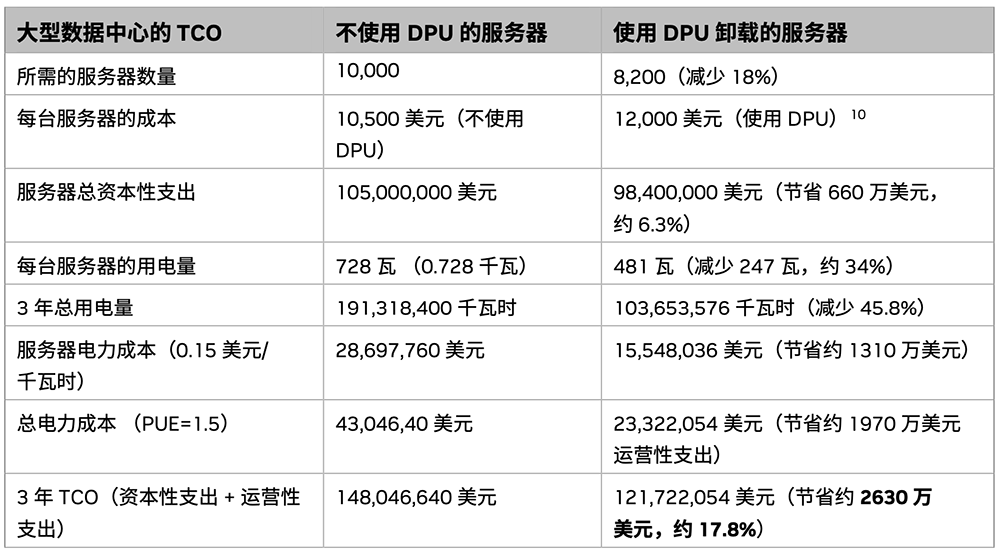
▲为拥有1万台服务器的小型网络系统排序将IPSec加密/解密装载到BlueField DPU的TCO(图源:NVIDIA DPU能效白皮书)
如此显著的成本优化,得益于英伟达极有远见的前瞻性布局:将硬件做到业界操控性标杆,用软件培养开发者习惯,从而构建一个普适的高效能生态环境。

开业界先例
实现公有云上的销售业务操控性隔离
与GPU如出一辙,提及DPU,英伟达绝对是被最先想起的公司,足见英伟达在业界的影响力。
而软硬“双剑合璧”,加上在生态合作和口碑方面的优势滚雪球般越滚越大,长期是英伟达能够站在潮头、难以复制的杀手锏。
硬件上,NVIDIA BlueField DPU在本地Host Memory和远端Host Memory之间建立了一条直接的通讯通道,整个过程不需要CPU分神参与任何通讯操作,并通过提供更多Pre-Active拥塞控制控制技术实现操控性隔离。
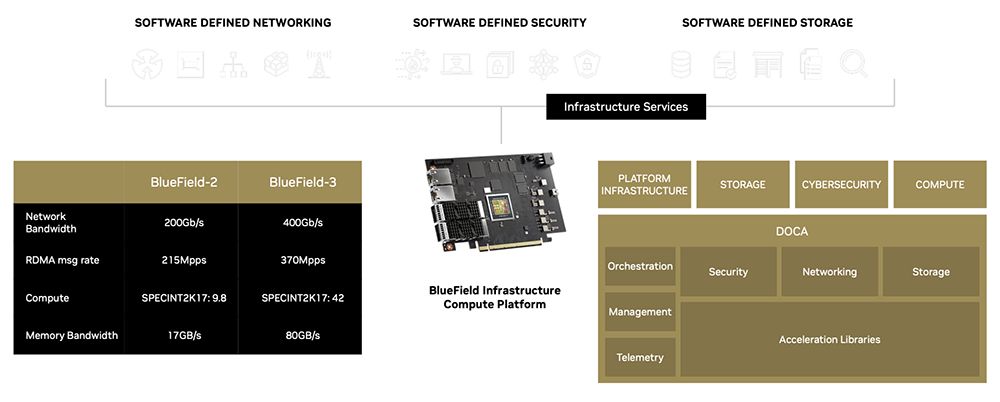 ▲DPU硬件与DOCA软件协作(图源:NVIDIA)
▲DPU硬件与DOCA软件协作(图源:NVIDIA)而硬件操控性的充分发挥,离不开大量的软件工作。针对BlueField DPU,英伟达打造了NVIDIA DOCA来提供更多各种加速库及标准编程接口,为其客户不断降低相应应用的DPU开发门槛。
再加上与英伟达其他先进网络控制技术的协同配合,网络系统的网络顽疾得以有效优化,能够更充分地发挥硬件天然资源的操控性。
这些优势的叠加,推动云原生植物DT排序控制技术走向破冰。新一代典例便是在HPC云服务方面一马当先的云巨擘微软智能化云Azure,在英伟达BlueField DPU相关产品及控制技术的支持下,它在业界率先实现了公有云上的销售业务操控性隔离。
也就是说,让销售业务在云上拥有像独享天然资源时一样的高效能水平,已经从设想转变为现实。
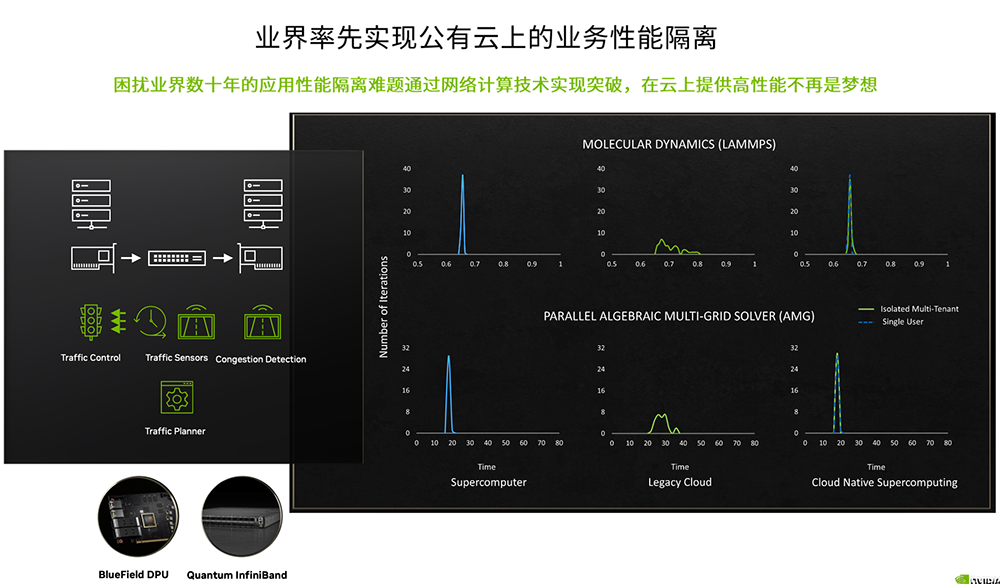 ▲借助云原生植物DT排序控制技术,Azure在业界率先实现公有云上的销售业务操控性隔离(图源:NVIDIA)
▲借助云原生植物DT排序控制技术,Azure在业界率先实现公有云上的销售业务操控性隔离(图源:NVIDIA)NVIDIA网络亚太区高级总监宋庆春告诉记者,如果现有公有云想将排序平台升级云化原生植物DT排序,可以先从英伟达BlueField DPU或标准网卡着手,在新体验到相应的控制技术优势后,在逐步演进至更多网络排序控制技术的替换,最终改造成基于云原生植物DT排序的最优排序平台。
目前云原生植物DT排序主要应用于面向高效能销售业务的穗序,包括现代高效能排序销售业务(如气象预测、石油勘探、生命科学等应用)、大规模AI训练各项任务、推荐各项任务等,并通过多项测试,验证了NVIDIA BlueField DPU在提高网络系统操控性和能效的真本事。
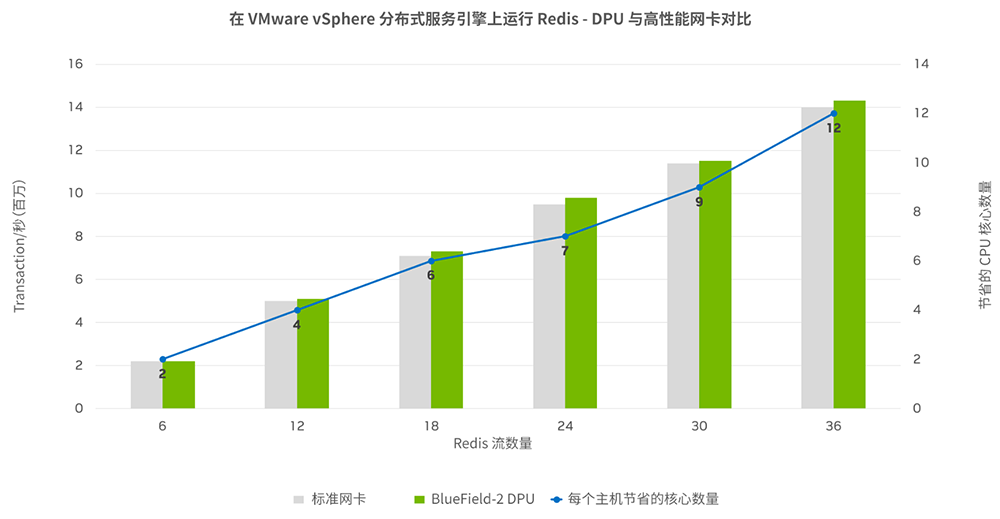
例如,Vmware和英伟达在服务器上测试Redis键值储存的测试表明,在25Gb/s网络上运行Redis工作负载的VMware vSphere分布式服务引擎时,将网络功能装载到NVIDIA BlueField DPU上,可释放12个CPU核心理念,同时提高Redis的操控性。
相比不使用DPU,使用NVIDIA BlueField DPU装载,可为近万台服务器3年节省约5650万美元(近4亿人民币)的总体拥有成本。
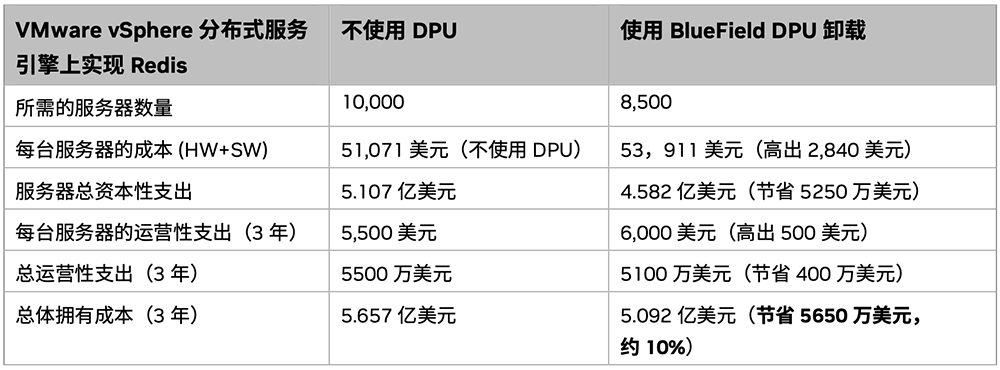
▲将VMware ESX网络功能装载到DPU后的TCO排序结果,其中Redis工作负载最初运行在1万台服务器上,并支持每台服务器每秒处置1400万个Redis事务(图源:NVIDIA DPU能效白皮书)
面向小型科研项目,通过DPU加速通讯,分子动力学模型操控性可提高20%,数据建模应用实现26%的操控性提高,天气预告模型实现约24%的操控性提高。即将走向市场的NVIDIA BlueField-3 DPU将支持400G带宽,内存平衡较上一代提高4倍。
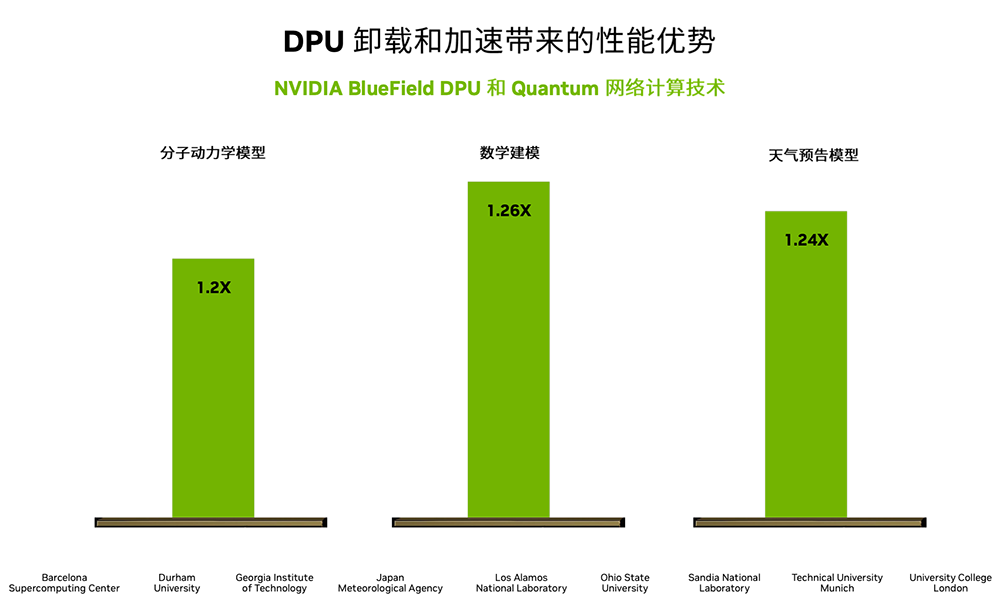 ▲DPU装载和加速带来的高效能排序操控性优势(图源:NVIDIA)
▲DPU装载和加速带来的高效能排序操控性优势(图源:NVIDIA)内置NVIDIA BlueField DPU的NVIDIA Quantum InfiniBand网络平台,也已经在DT排序领域功勋赫赫,并在全球超算榜单中展现出愈来愈高的存在感。以新一代全球IO500高效能储存网络方案榜单为例,10节点测试中,前4名系统均采用NVIDIA Quantum InfiniBand网络。
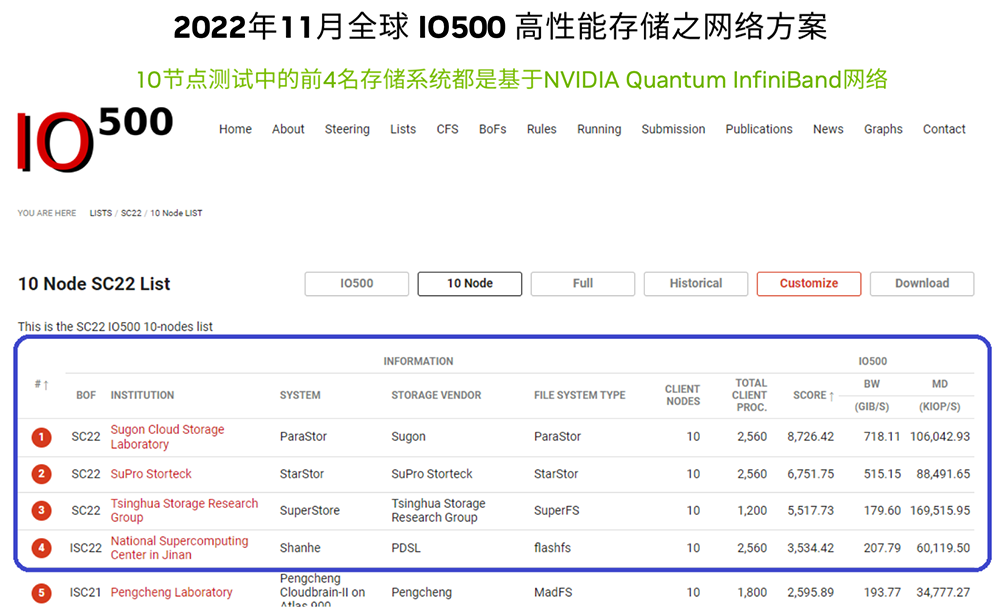 ▲2022年11月全球IO500高效能储存网络方案榜单(图源:NVIDIA)
▲2022年11月全球IO500高效能储存网络方案榜单(图源:NVIDIA)
结语:释放云的力量
奔赴新型网络系统今后
2020年秋季,当“晶片圈知名带货王”NVIDIA首席执行官黄仁勋在GTC大会上亮出DPU时,DPU对于不少云排序及DT排序从业者来说还是一个新鲜但不确定有多大价值的新概念。
今天,再谈起DPU,你也许会想起AWS Nitro,也许会想起阿里云CIPU,会想起英特尔IPU,抑或是这两年突然涌起的DPU创业与投资热潮。而引爆DPU概念的NVIDIA,已经低调地将重心转向部署,让“第二颗主力晶片”真枪实弹地进入一线网络系统客户的真实销售业务战场,作为云原生植物DT排序的灵魂,为网络系统展现新的构架可能。
如今,DPU正呈“神仙打架”之势,通过推动网络和排序构架的创新,它将帮助小型网络系统的建设者们穿越周期,奔赴一个高排序密度、智能化集约、绿色低碳、安全可靠的网络系统今后。

.jpg)
.jpg)
.jpg)

.jpg)

.jpg)
.jpg)
.jpg)


.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
