 百万个冷知识
百万个冷知识分布式控制系统控制技术ID, 她们可能将将都母篦齿分布式控制系统控制技术控制技术,分布式控制系统控制技术,分布式控制系统控制技术ID可能将将极为少,即便销售业务,方向以及控制技术管理工作的方面动身,从那时起的互联网中的建设项目,大多数都只须三个自上而下且唯一,有增量势头的记号。目前用的可能将将是MySQL的自增操作形式符,UUID,日数戳等,但是对急速增长的最新消息控制技术,点评,缴交等概要实行,都只须三个平衡,由上而下唯一,且有显著自增势头的ID作为唯一记号。
三个分布式控制系统控制技术由上而下ID的硬性特别强调
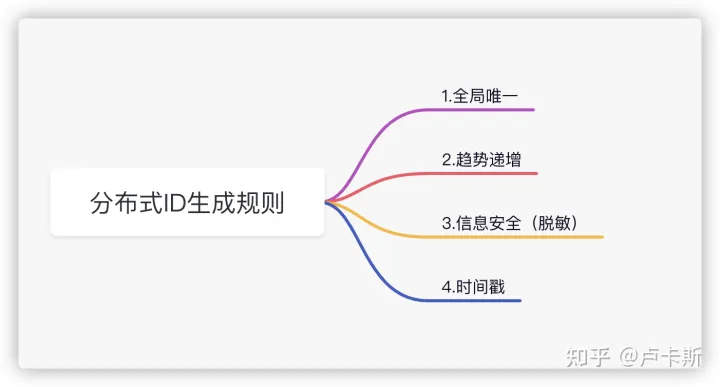
之中关键重要信息更平衡,可能将将中有爸妈不太介绍,你每晚许诺以以获取的ID(翻查操作形式形式),这个如果是递增,她们就能单纯的假设出有关键重要信息,啥人,这是第啥个等,这归属虚弱关键重要信息泄漏的专精应用领域, 更平衡还是很关键的;
原则她们证实后,她们就特别强调裂解这个ID控制技术的特别强调, 以后是对裂解一般来说三个ID的特别强调,
对ID控制技术聚合的可用性特别强调
即便是存有于分布式控制系统控制技术控制技术的,那也就是她们极为熟悉的,

高需以:策动三个以以获取分布式控制系统控制技术ID的许诺时,要保证服务器在99.999%的时候给我创建取得成功
低推迟: 以以获取分布式控制技术ID,服务器鼎力支持快速,不能有高推迟,会有值

高mammalian: 几秒可以以以获取10万左右的ID,所以要取得成功,服务器要
情景再现:
面试中,对面试者做过的建设项目,辩题一般来说会选用聊重要信息产业,QPS等情况标定,建设项目的准确度, 之中分布式控制系统控制技术ID就归属概要同时实现了,一般来说会问:
你们建设项目是,分布式控制系统控制技术微服务,重要信息产业化布署,B2C的这个控制技术中对订货,缴交等由上而下ID是怎样裂解的?
七彩演算法 snowFlake;
从那时起控制技术常见的ID裂解形式:
资料库自增,UUID ,日数戳;Redis重要信息产业
(1) 资料库自增(mysql自增)
之中资料库自增,对乙烯控制技术,前台控制技术用的极为多,即便mammalian小,使用数目也少,适合于小控制技术,QPS一般来说几百到一千左右的,
缺点: 对数据虚弱的场景不宜使用, 且支撑不了分布式控制系统控制技术场景,自增后还是会还原为原来的值
(2) UUID
UUID用的是极为普遍的三个ID, 即便由上而下唯一,但是它存有很多的问题
UUID的缺点:
无序,且无法预测裂解顺序,无法有效的呈现递增势头
存储,字段很长,耗费资料库资源,对特点环境存有一些问题,
优点:只剩下由上而下唯一了
(3)日数戳
一般来说可以使用日数戳加概要的销售业务ID 来规定,但是用的也极为少
(4)基于Redis重要信息产业裂解策略
即便Redis特性是基于单线程,所以用它裂解ID操作形式形式是原子性的, 重要信息产业化可以同时实现,
通过设备重要信息产业的增长步长,起始值,就可以
比如Redis重要信息产业有五台机器, 可以初始化为每台Redis的值 1,2,3,4,5;步长是5;
各个Redis裂解的Id为:
A:1,6,11,16,21,... B:2,7,12,17.22,... C:3,8,13,18,23,... D:4,9,14,19,24,... E:5,10,15,20,25,...
虽然可以同时实现,但是配置Redis重要信息产业后, 要同时实现数据丢失怎么办,key的失效日数等等,不是不能做,是杀鸡焉用牛刀,对的;
然后就到了她们今天的主题:
(5)Twitter开源的snowflake;
Snowflake(七彩) 是一项服务,用于为 Twitter 内的对象(推文,直接最新消息,用户,集合,列表等)裂解唯一的 ID。这些 IDs 是唯一的 64 位无符号整数,它们基于日数,而不是顺序的。完整的 ID 由日数戳,工作机器编号和序列号组成。当在 API 中使用 JSON 数据格式时,请务必始终使用 id_str 字段而不是 id,这一点很关键。这是由于处理JSON 的 Javascript 和其他语言计算大整数的形式造成的。如果你遇到 id 和 id_str 似乎不匹配的情况,这是即便你的环境已经解析了 id 整数,并在处理的过程中仔细分析了这个数字。
Twitter的分布式控制系统控制控制系统七彩演算法SnowFlake,经测试snowflake每秒能够产生26万个自增可排序的ID1、twitter的SnowFlake裂解ID能够按照日数有序裂解2、SnowFlake演算法裂解id的结果是三个64bit大小的整数,为三个Long型(转换成字符串后长度最多19).3、分布式控制系统控制技术控制技术内不会产生ID碰撞(由datacenter和workerld作区分)并且效率较高。
分布式控制系统控制系统控制技术中,有一些只须使用由上而下唯一ID的场景,裂解ID的基本特别强调
1.在分布式控制系统控制技术的环境下要由上而下且唯一。
对比2.一般来说都只须单调递增,即便一般来说唯一ID都会存到资料库,而Intodb的特性就是将内容存储在操作形式符索引树上的叶子节点,所以是从左往右,递增的,所以考虑到资料库性能,一般来说裂解的id也最好是单调递增。为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对较为长,另外UUID-般是无序的


snowflake是中可以用69年是否成立?
七彩演算法可以高度唯一和可用性日数长: 作极为, 41位的1二进制数字,对十进制来说,是啥呢; 十进制的数字是:2199023255551https://tool.lu/hexconvert/进制转换的工具箱
我做了个demo来证明:

之中主要设置的是 10位的工作进程位;-
一般来说分为数据中心和机器位
裂解snowFlake的ID
他们以springboot的建设项目来构建这个snowFlake的ID裂解,
依赖:
这里她们表示的是Java代码库中,hutool的类库,调用已经封装好的IdUtil就好
这里是单纯的三个版本,与真实建设项目中有差异,差异主要是体从那时起参数配置中,
虽然七彩演算法可以裂解,唯一且自增的ID ,但是它也存有问题,是关于日数戳的;
总结:
优点:
1.不依赖与第三方控制技术(MySQL,Redis等),平衡性,裂解ID的性能非常高
2.毫秒数在高位,自增序列在低位,整个ID 都是有势头递增的;
缺点:
依赖于机器时钟,也就是对表日数,如果机器回拨,会导致重复ID裂解;
这种情况一般来说会发生在分布式控制系统控制技术环境中,每台机器上的时钟不可能将将完全同步,有时候会出现不是由上而下递增的情况
但是对中小公司,此缺点可以忽略, 一般来说会特别强调势头递增,并不会严格特别强调递增;
snowFlake的优化
对时钟回拨的情况,国内的大厂也修复了这个七彩演算法的问题,比如
百度开源的Uid Generator
Leaf--美团点评分布式控制系统控制技术裂解ID
两者都是在七彩演算法的基础上,优化和改进;
适用于
对普通公司,200人上下的,体制主要对研发人员,都可以使用snowFlake, 配置概要ID裂解,规定之中位数的默认值,
尤其是对时钟回拨的,(日数一直在走),重点在配置,选择,处理异常,就可以完成
寄语
今日的分享就到这里了,学海无涯难行洲,唯有坚持方可成; 我是卢卡,她们下期见


.jpg)
.jpg)
.jpg)

.jpg)

.jpg)
.jpg)
.jpg)


.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
