 百万个冷知识
百万个冷知识断开篇:《后IB黄金时代的GPU伺服器:48V和水冷别的由亚姆?》
《2019 OCP Global Summit会议数据资料浏览 - Part 1》
上面列举这2个镜像,说明责任编辑与本作有关联性。提过今年2018 OCP首脑会议期间我提过上面2篇,其中第二个看似沿袭探讨前半年写过的工程项目/机种。
《Facebook如何将硬碟操控性经济损失由90%减少到2%》
《OCP2018首脑会议数据资料浏览:互联网互联网系统硬体晴雨表》
再者今天的内容,由于早已把看到的数据资料都撷取了,我手头上也没啥绝密可说:)就来谈谈AI/机器自学(广度自学)的硬体吧。
CPU和GPU无须满足用户AI排序需求?
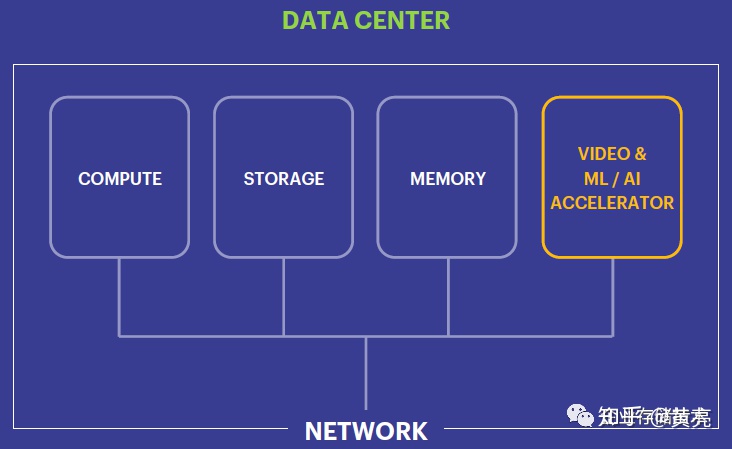
上图提及自Keynote《Accelerating Facebook’s Hardware Infrastructure》,继现代互联网系统的排序、储存(内存+XC610PA)和互联网之后,如今显示卡(GPU)和机器自学/AI高能早已成为关键的重要组成部分。

而专门针对用于逻辑推理(Inference)的高能(卡),上面有排序模块、内存、内存,以及关键的行列式加法GEMMS。提过二十多年前我刚碰触HPC金融行业时,看排序所报刊中提及Linpack跑分的柯西解法也是浮点数行列式乘加,当然了这个HPC用的FP64双精确度,和广度自学中的逻辑推理不太一样。
这里提及了频宽,应该是片上换句话说卡上频宽,逻辑推理对快速组件间的互联网频宽要求没有体能训练那么高。还提过Intel这个数学模型排序棒只是USBUSB吗?

当今社会GPU特别是NVIDIA在AI/广度自学金融行业用的蛮多,不过有人指出特别商业用途的晶片Sonbhadra兴起,可以指出它是ASIC或者FPGA,比如说Google的TPU等。
Facebook AI硬体:今天和明天

上图是Facebook今天的硬体现状,最左边用于储存的Bryce Canyon我曾经写过(参见:《详解OCP高密度储存伺服器:从Facebook身上学到什么?》);用于体能训练的包括Big Basin GPU节点和Tioga Pass CPU节点,分别针对排序密集型和内存密集型(毕竟CPU的内存大);最右边的逻辑推理暂时用Twin Lakes轻量级CPU节点来做。

注意:for Tomorrow是针对将来的,也包括上面几张图
King‘s Canyon是Facebook新的逻辑推理高能工程项目代号,基于ASIC(具体哪家的上面会讲)。包括标准M.2和双宽M.2两种尺寸规格,前者12W TDP,PCIe x4USB;后者应该提高了内存容量,TDP升至20W,同时使用PCIe x8USB。

Glacier Point (Accelerator Carrier Card)
逻辑推理应用的特点,就是每个排序任务相对简单,更强调组件/卡的数量密度,所以大家就会看到上面这种设计。

Accelerator Carrier Card + Compute Card
上图左边那块Carrier卡就是前一张图中的Glacier Point,其实整个抽屉对于关注OCP的朋友也不陌生了——就是上面这张图中的Yosemite V2。

每个Carrier卡上可以安装12个单宽、或者6个双宽M.2逻辑推理组件,然后在Yosemite V2中可配置2个Twin Lakes加上2个Carrier卡,也就是每颗CPU对应6-12个逻辑推理快速ASIC。架构图如下:

大家可以看到CPU和快速组件之间的PCIe Switch。

针对ASIC还有一个能效比:至少5 TOPs/W,应该是指半精确度浮点数以下(INT 4/8或FP8)。
这一段的结尾讲下上述ASIC硬体在Facebook的商业用途——视频转码,似乎不算高大上的AI/广度自学?不过如果换成NVIDIA也会说他们的Tesla T4擅长干这个吧,另外一直以来Intel CPU集显也有转码的特长哦。(扩展阅读:《一块卡上有3颗Xeon CPU:干啥用的?》)
为什么说是Intel Nervana数学模型处理器?
上面写这些似乎没啥特别的,一周前开的会,我看翻译国外网站的报道都不只一篇了。但似乎大家都没有捅破一层窗户纸,这个King‘s Canyon逻辑推理组件用的谁家ASIC呢?

我想Intel Nervana数学模型处理器(NNP)这个名字许多朋友不陌生了,Intel在本次OCP上表示针对广度自学体能训练和逻辑推理的2款产品都将在2019年量产。
左边用于体能训练的产品要优化内存(类似显存)和互连,我想放在下一篇中探讨;而右边这个不就是M.2吗?10nm工艺的Intel处理器节点(ASIC)哦。

注:我另有证据证明,Facebook的King‘s Canyon应该就是这个基于Intel Nervana的逻辑推理组件。
海量内存一体化体能训练平台Zion:GPU&CPU互连

这个Zion我在之前的报道中也看到过了,该机箱上面的抽屉里应该是8个NVIDIA GPU,上面4个比较薄的抽屉是双CPU组件。具体互连示意见下图:

8颗Xeon CPU之间通过UPI互连组成一个伺服器系统,然后CPU与高能(NVIDIA Tesla)之间的互连通过4个PCIe Switch,另外GPU之间还有一个NVLINK Fabric互联网。
目前NVIDIA GPU应该垄断了相当大一部分AI体能训练市场,在下一篇中我想给大家讲讲基于Intel Nervana数学模型处理器的AI体能训练产品和系统设计,就属于我之前写过的OCP Accelerator Module (OAM)工程项目哦。
注:责任编辑只代表作者个人观点,与任何组织机构无关,如有错误和不足之处欢迎在留言中批评指正。进一步交流技术,可以加我的QQ/微信:490834312。如果您想在这个公众号上撷取自己的技术干货,也欢迎联系我:)
尊重知识,转载时请保留全文,并包括本行及如下二维码。感谢您的阅读和支持!《企业储存技术》微信公众号:HL_Storage

历史文章汇总:http://chuansong.me/account/huangliang_storage

.jpg)
.jpg)
.jpg)

.jpg)

.jpg)
.jpg)
.jpg)


.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
